Scientific Python - first contact
To be honest, my last contact with Python was some years ago. It’s a pretty cool language, nice packaging system (pip and so on) like CPAN1 or CTAN2. But to be more focused on C/C++, Python and myself are going different ways. Last year I purchased a textbook “Python Machine Learning” Sebastian Raschka in a fortunate coincidence and as I had read it, I was fascinated by a bundle of new Python libraries like Numpy, SciPy, Mathplotlib and so on.
First contact and results Link to heading
For data machining, there’re lots of tools inside these packages and they are able to compete with such huge software packages like Mathworks MATLAB3. Of course, MATLAB is in most cases the first choice for quick results and spontaneously written scripts. But there are lots of advantages like the platform independence, there existing Open Source licensed packages and it is highly automatable.
So in preparation for a presentation, I was tinkering with these Python packages and was able to generate these nice bivariate distributions. They are running on my office system (Windows 7), on my private MacBook and of course on my CI4 server. A win-win-win situation I guess.
Results Link to heading
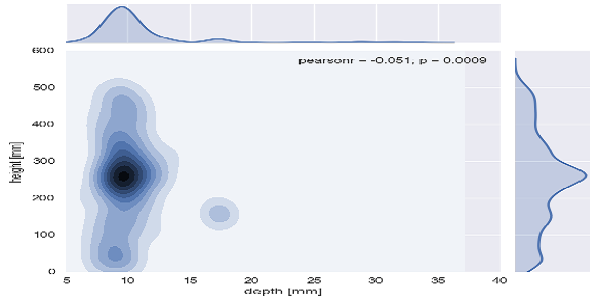
Bivariate distribution #1
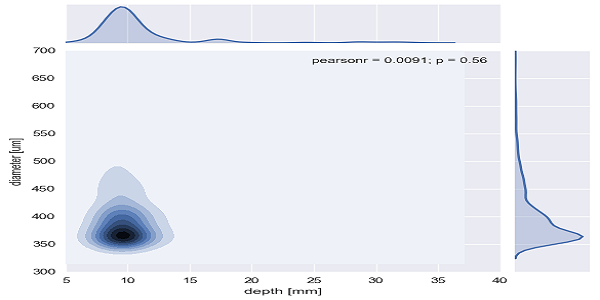
Bivariate distribution #2
Conclusion Link to heading
As I mentioned “Scientific Python” is a great way for data processing and visualization.